Benchmarking CRuby, MJIT, YJIT, JRuby and TruffleRuby
In this blog post we benchmark many Ruby versions and the latest Ruby Just-in-Time compilers (JITs) on the newest Ruby benchmark suite, yjit-bench. As a teaser, the geometric mean speedups compared to CRuby 3.1 on these 14 benchmarks are: MJIT 1.26x, YJIT 1.39x, JRuby 1.86x and TruffleRuby 6.23x. Read on to find more about the benchmarks and gain insights on these speedups. This blog post is also available on Medium.

Outline
Approach
Rubies
We benchmark the following Ruby versions:
- CRuby 2.0:
ruby 2.0.0p648 (2015-12-16 revision 53162) [x86_64-linux] - CRuby 2.7:
ruby 2.7.5p203 (2021-11-24 revision f69aeb8314) [x86_64-linux] - CRuby 3.0:
ruby 3.0.3p157 (2021-11-24 revision 3fb7d2cadc) [x86_64-linux] - CRuby 3.1:
ruby 3.1.0p0 (2021-12-25 revision fb4df44d16) [x86_64-linux] - CRuby 3.1+MJIT:
ruby 3.1.0p0 (2021-12-25 revision fb4df44d16) +MJIT [x86_64-linux] - CRuby 3.1+YJIT:
ruby 3.1.0p0 (2021-12-25 revision fb4df44d16) +YJIT [x86_64-linux] - JRuby+invokedynamic, on the system JDK 11:
jruby 9.3.2.0 (2.6.8) 2021-12-01 0b8223f905 OpenJDK 64-Bit Server VM 11.0.10+9 on 11.0.10+9 +indy +jit [linux-x86_64] - TruffleRuby JVM EE (JDK 11):
truffleruby 22.0.0-dev-9bdb2dfc, like ruby 3.0.2, GraalVM EE JVM [x86_64-linux]
We ran all the benchmarks on 4 January 2022 on an AMD Ryzen 7 3700X 8-Core Processor, with 32GB of memory and a NVMe M.2 SSD, on Linux.
We chose CRuby 3.1 as the baseline (= 1.0x) in order to easily compare how much MJIT and YJIT gain over CRuby without JIT (the default).
CRuby 2.0 can only run a small subset of the benchmarks. CRuby 3.1 includes both MJIT and YJIT which makes it convenient to measure them. For TruffleRuby we picked a single variant (out of Native/JVM CE/EE) to keep the charts readable as there are already many Ruby implementations. We used TruffleRuby from the release branch of the upcoming GraalVM 22.0.
yjit-bench
We run all 14 macro benchmarks from the yjit-bench benchmark suite at commit 1751916ceb, except for the jekyll benchmark because it is very noisy and does not work on several Ruby versions.
We do not report the micro benchmarks (example), since those seem to be there mostly to tweak JITs rather than to compare general Ruby performance. Of course micro benchmarks do not represent anything close to a real workload.
As a fun fact, TruffleRuby optimizes away (>1000x faster) half of those micro benchmarks.
The yjit-bench benchmark suite contains a variety of benchmarks, and is maintained principally by Noah Gibbs (who also worked on benchmarks for Ruby 3x3) and Maxime Chevalier-Boisvert (leading YJIT) at Shopify.
One significant advantage of this benchmark suite is all benchmarks are really easy to run, any setup (including bundle install and db:migrate) is done automatically and running a benchmark is just ruby -I./harness benchmarks/some/benchmark.rb.
There are no subprocesses, no magic, and so it is really easy to run them and profile them.
Warmup
We measure peak performance, i.e., performance after enough warmup, that is performance after the relevant methods are compiled. This is what is typically used to compare JITs, and it is also what this benchmark suite aims to measure. All benchmarks were run with enough warmup. The warmup is automatically detected by using a custom harness which tracks the median absolute deviation over all iterations so far and keeps running more iterations until the median absolute deviation threshold is reached (more details here).
In general, more advanced JITs need more warmup. The TruffleRuby and GraalVM teams are working on this issue by using multi-tier compilation, persisting the JITed code and optimizing interpreter performance, among other ideas.
The plots report the median as the bar heights and the median absolute deviation as error bars, for the second half of all iterations run. The first half is considered warmup and typically more noisy. Those estimators are chosen because they are robust (which means they are not affected by outliers like a GC in one iteration), unlike the usual mean and standard deviation. As one can see, the error bars are very small for almost all benchmarks, which is a further indication of enough warmup and having reached stable performance.
The median is the middle value when we sort all values. The median absolute deviation is the median of all absolute deviations, which are the absolute value of the difference between a given value and the median. In other words, the median represents the middle value (typically the closest value to most values), and the median absolute deviation shows us how far other values are from the median.
Benchmarks
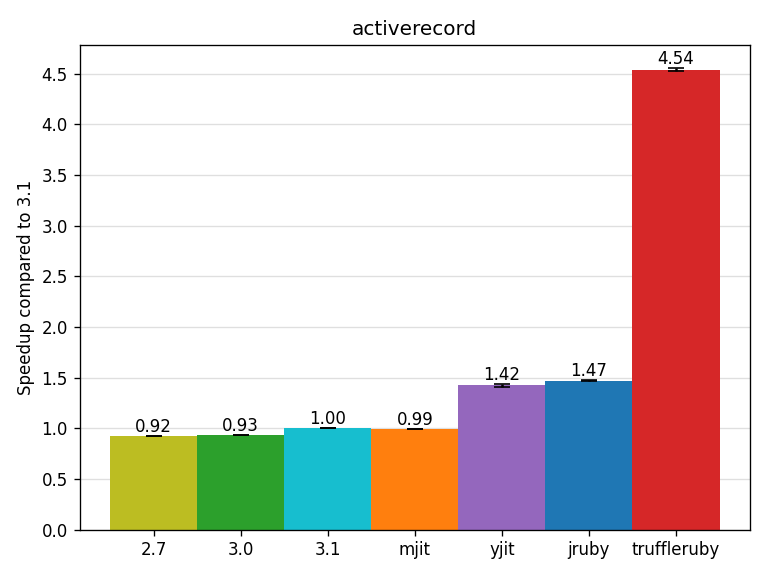
The activerecord benchmark uses Rails’ ActiveRecord to query the database and return the title of the first Post.
The sqlite3 in-memory database is used for convenience (sqlite3 is a C extension gem).
On JRuby, activerecord-jdbcsqlite3-adapter is used instead.
One might think this benchmark is dominated by database performance but it seems clearly not the case, with YJIT being 1.42x the speed of CRuby 3.1 and TruffleRuby showing a 4.54x speedup.
There is quite a bit of Ruby logic in ActiveRecord and some in the sqlite3 gem, which Ruby JITs can potentially optimize.
TruffleRuby might also run the C extension faster since TruffleRuby JIT-compiles C extensions together with Ruby code.
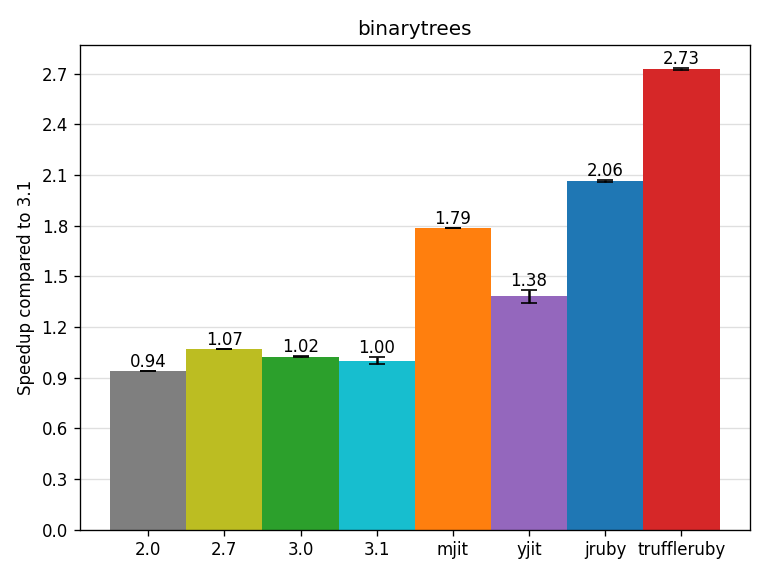
The binarytrees benchmark (from the Computer Language Benchmarks Game, abbreviated CLBG later) creates binary trees using lots of recursive calls. It also stresses the GC due to many allocation and keeps one tree alive for a while. MJIT is doing well here with a 1.79x speedup, JRuby 2.06x and TruffleRuby 2.73x.
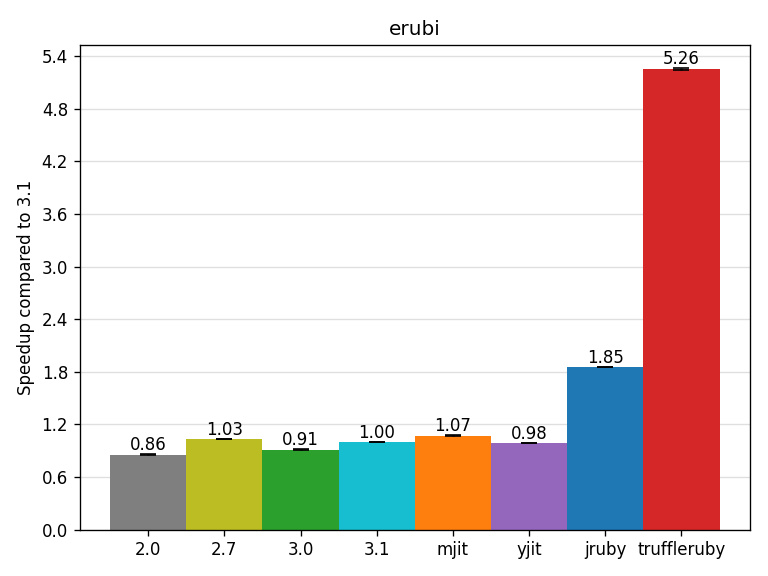
The erubi benchmark renders an ERB template (gem server’s index with 322 gems) using the erubi gem, which is the default template engine in Rails.
The rendered template has a length of 166563 bytes.
TruffleRuby performs great here due to its very efficient String concatenation and achieves a 5.26x speedup.
YJIT is currently not optimizing this benchmark well due to not supporting a bytecode instruction used in this benchmark.
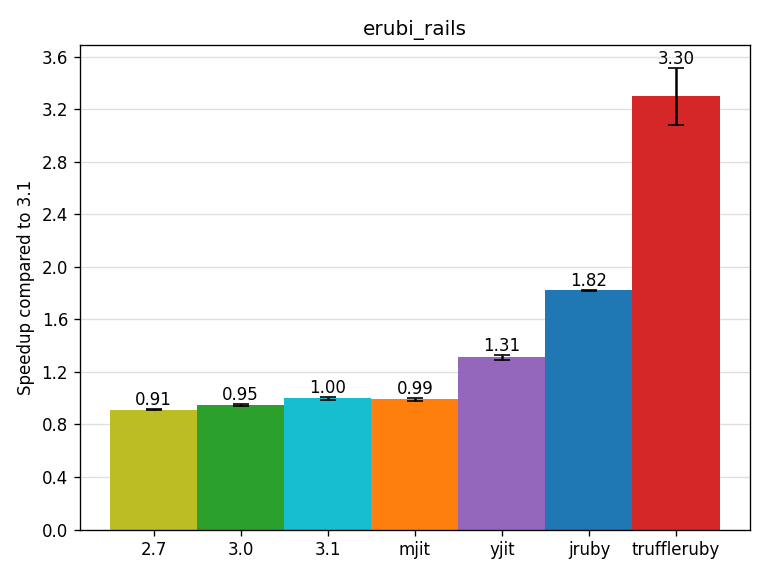
The erubi_rails benchmark is a small Rails application which renders an ERB view coming from Discourse.
The rendered template has a length of 9369 bytes.
The benchmark renders a topic’s page 100 times per iteration, in process (no network involved).
No database is involved in this benchmark as it focuses on erubi in the context of Rails.
YJIT gets a speedup of 1.31x, JRuby of 1.82x and TruffleRuby of 3.3x.
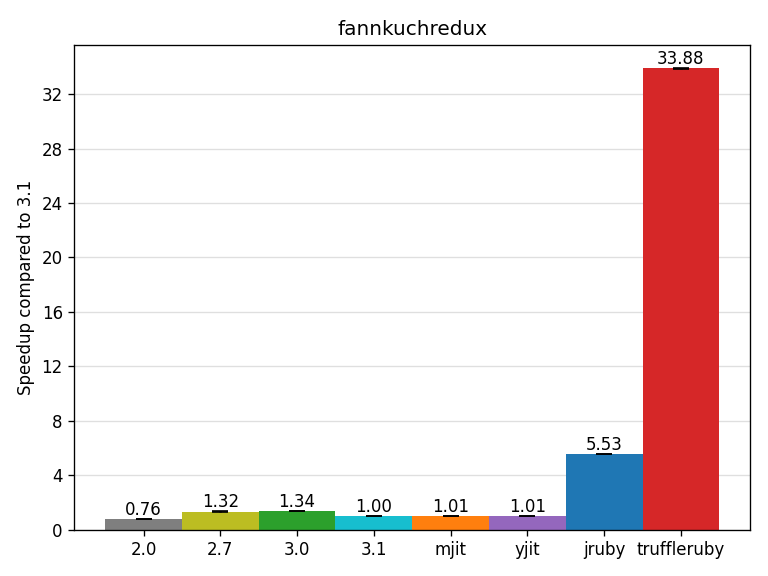
The fannkuchredux benchmark (from CLBG) creates and manipulates Arrays extensively.
MJIT and YJIT seem to not achieve any speedup here, probably because the benchmark is heavy on Array operations and Array operations are defined in C in CRuby and so MJIT/YJIT cannot optimize them (except for simple a[i] and a[i] = v but they do not seem to optimize it better than the interpreter in this benchmark).
JRuby and TruffleRuby OTOH can optimize and JIT compile Array operations, and TruffleRuby uses storage strategies for Arrays.
JRuby gets a speedup of 5.53x, TruffleRuby gets a speedup of 33.88x.
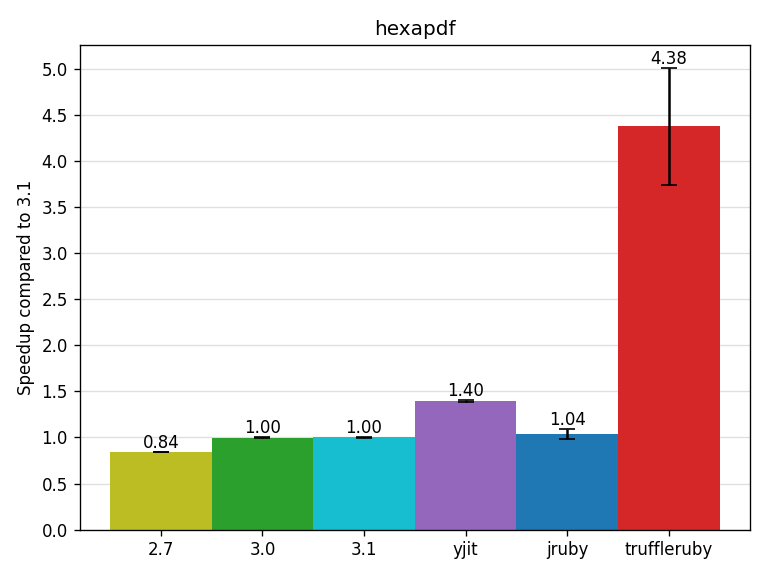
The hexapdf benchmark uses the hexapdf gem, wraps a long text (The Odyssey) to a line width of 50 characters and renders it to a PDF file, saved to /tmp. hexapdf is written entirely in Ruby (no C extension).
Wrapping text is heavy on arithmetic operations and JITs often do a good job on those.
YJIT gets a speedup of 1.4x, TruffleRuby of 4.38x (with some variability).
CRuby 3.1 MJIT fails this benchmark with buffer error (Zlib::BufError).
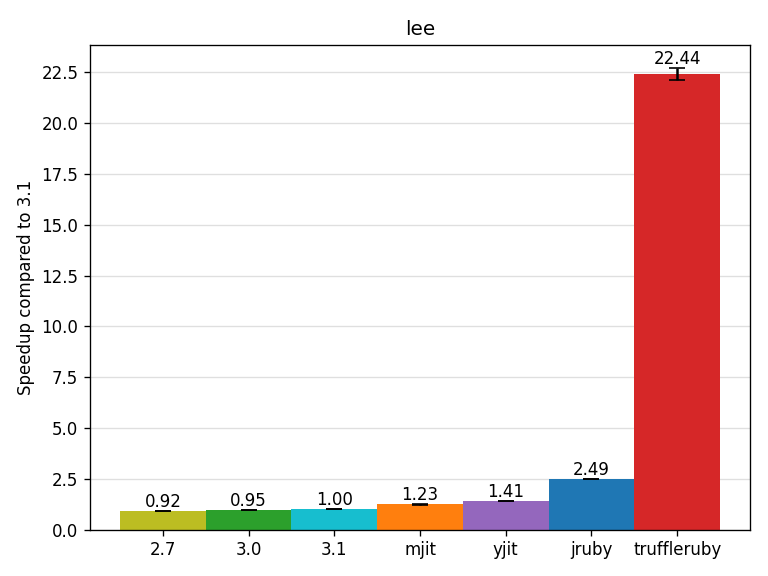
The lee benchmark is from Chris Seaton (see his blog post) and some of his work during his PhD. The benchmark lays out the wires on a circuit board in a manner which avoids crossing wires. This is the sequential version of the benchmark. It seems worth noting the approach itself is from scientific literature and Chris wrote this in straightforward pure Ruby, not particularly optimizing it for any Ruby implementation. In his blog post he found that TruffleRuby was over 10x faster than CRuby 2.7. On latest TruffleRuby, we see a speedup of 22x!
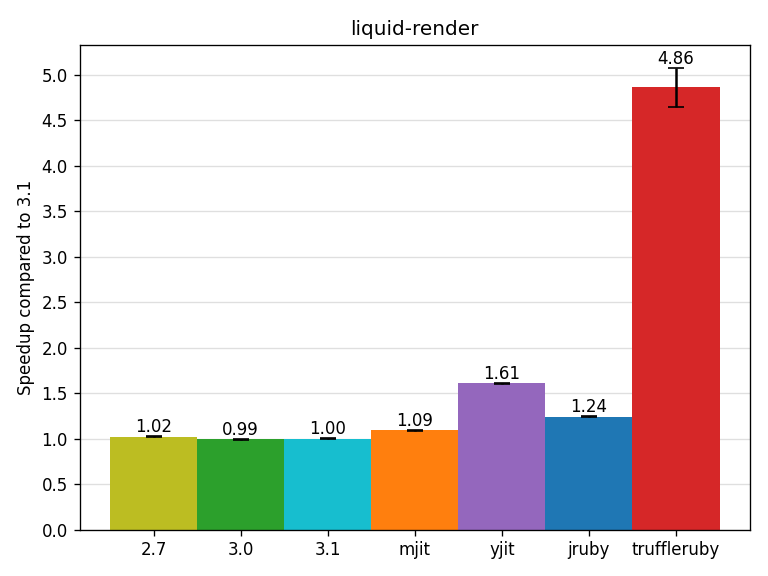
The liquid-render benchmark renders all the performance test Liquid templates which are parsed before starting the benchmark.
As you may know, rendering Liquid templates quickly is important for Shopify.
Liquid is not a typical template engine, it does not generate Ruby code and eval it and then call the generated method (like ERB engines).
Instead, Liquid interprets an AST representing the template for security reasons and avoiding eval.
YJIT gets a speedup of 1.61x and TruffleRuby gets a speedup of 4.86x, some of it due to TruffleRuby’s advanced String representation (Ropes) and the rest due to JIT compiling the Liquid interpreter better.
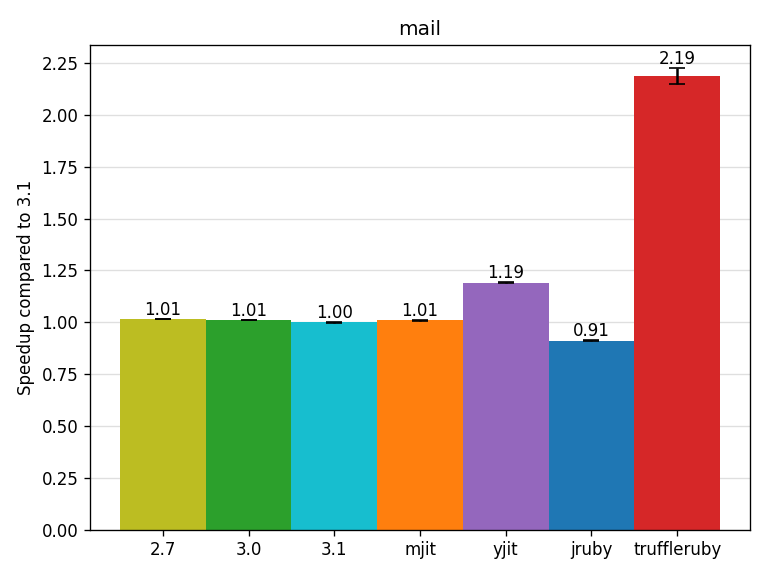
The mail benchmark parses an email with the mail gem (more context). Some of the parsing is done by parsers generated by Ragel.
YJIT and TruffleRuby show nice speedups.
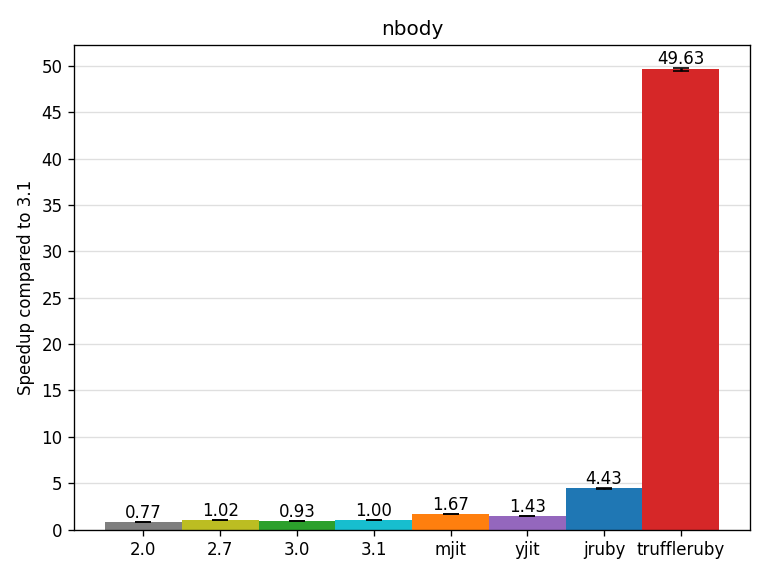
The nbody benchmark (from CLBG) models the orbits of Jupiter, Saturn, Uranus and Neptune around the Sun. The benchmark consists mainly of arithmetic computations and accessing instance variables heavily (planets are represented as objects). JRuby reaches a good speedup of 4.43x. TruffleRuby is about 50x the speed of CRuby 3.1, which is simply incredible.
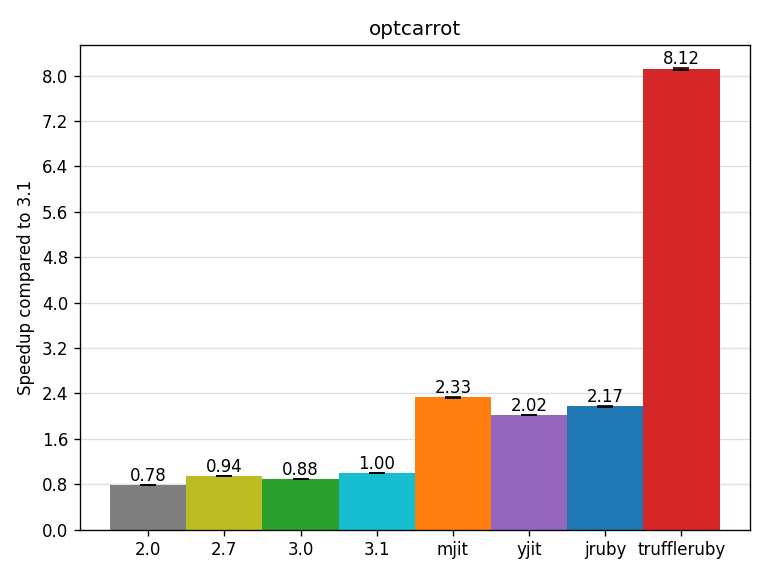
The optcarrot benchmark is one of the famous benchmarks for Ruby 3x3 (by @mame, my blog post about it). It is a NES emulator and this benchmark renders 200 frames of the Lan Master game per iteration.
MJIT is known to be about 3x faster than CRuby 2.0 on this benchmark.
In this run, 3.1 MJIT is exactly 3.0x as fast as CRuby 2.0.
TruffleRuby is known to be good at it since the benchmark came out, and it reaches a 10.4x speedup over CRuby 2.0.
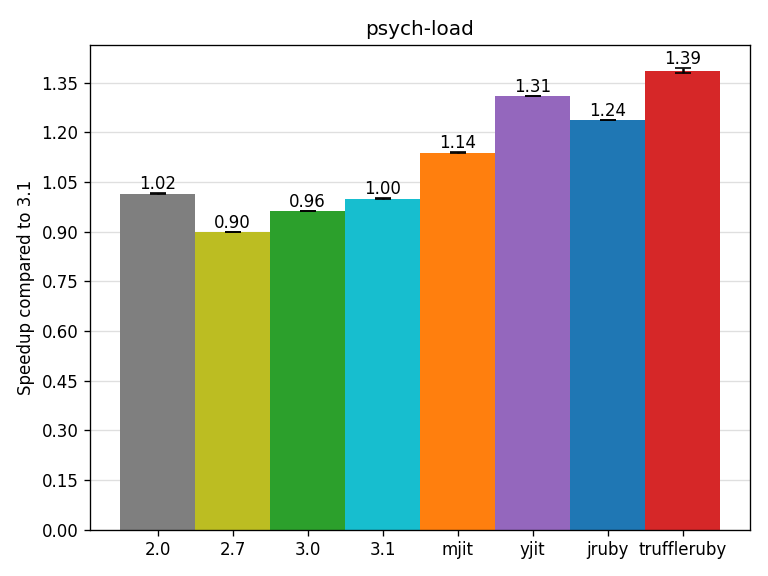
The psych-load benchmark parses a set of YAML files using Psych.load (same as YAML.load).
Psych 2.2.4 is used on CRuby 2.0 instead of Psych 4.0.1, since it is the latest Psych version compatible with 2.0.
Although a significant part of the benchmark is likely spent inside the psych C extension (which uses the libyaml YAML parser), we see the time is not only spent in C extensions (where CRuby JITs cannot help) but also in Ruby code as MJIT and YJIT show some speedups here.
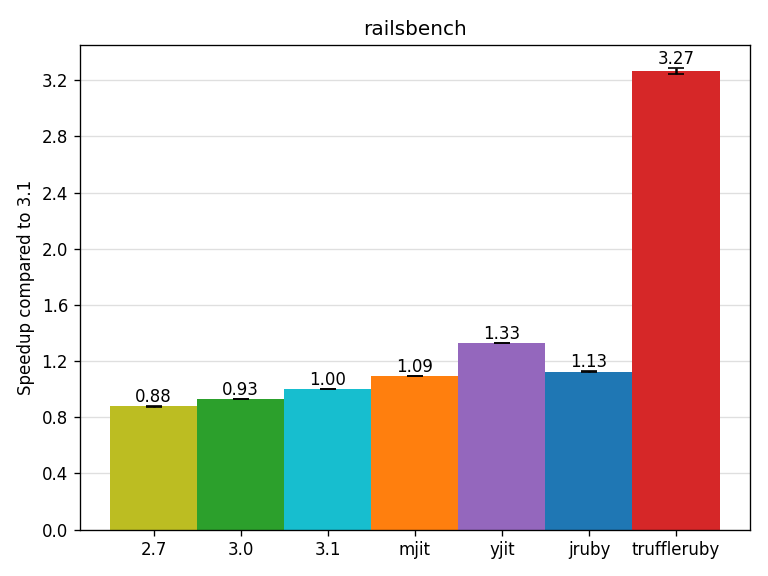
The railsbench benchmark is inspired from k0kubun’s railsbench, which is based on headius’s pgrailsbench. It is a small blog-style Rails app scaffolded with a Post model. This variant uses sqlite3 as the database for convenience (stored on disk), and runs everything in a single process (much simpler to run).
The benchmark repeatedly visits the index of the posts (both as HTML and JSON) and each of the 100 posts in a pseudorandom order with a fixed seed. It uses the default ERB templates generated by Rails.
MJIT gets a speedup of 1.09x (it took a while for MJIT to speedup Rails), YJIT of 1.33x, JRuby of 1.13x and TruffleRuby of 3.27x.
In other words, on this small Rails benchmark, TruffleRuby response times are more than 3 times faster than CRuby 3.1!
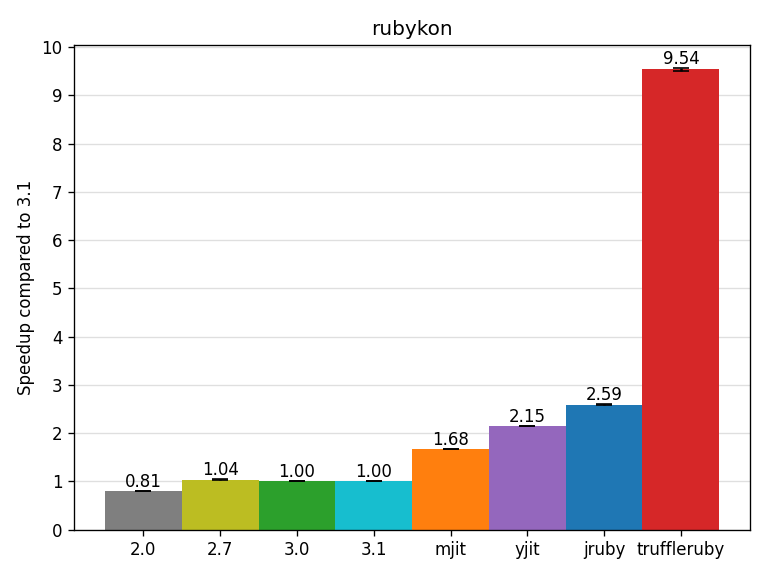
The rubykon benchmark (by @PragTob) is well known from the blog posts by its author. Rubykon is an AI for the Go board game. YJIT reaches a 2.15x speedup and JRuby 2.59x. TruffleRuby is ahead with a 9.54x speedup.
Summary
The benchmarks we just analyzed are of various size and have many different characteristics, notably some are more realistic and some less.
I think a geometric mean over their results alone is not really a good summary given the variety.
But yet, it is nice to have a one-number summary for these benchmarks.
Note that CRuby 2.0 can only run 7 benchmarks out of 14, and MJIT runs 13 out of 14 (not hexapdf).
The others Ruby versions run all 14 benchmarks.
Error bars are not meaningful on this chart.
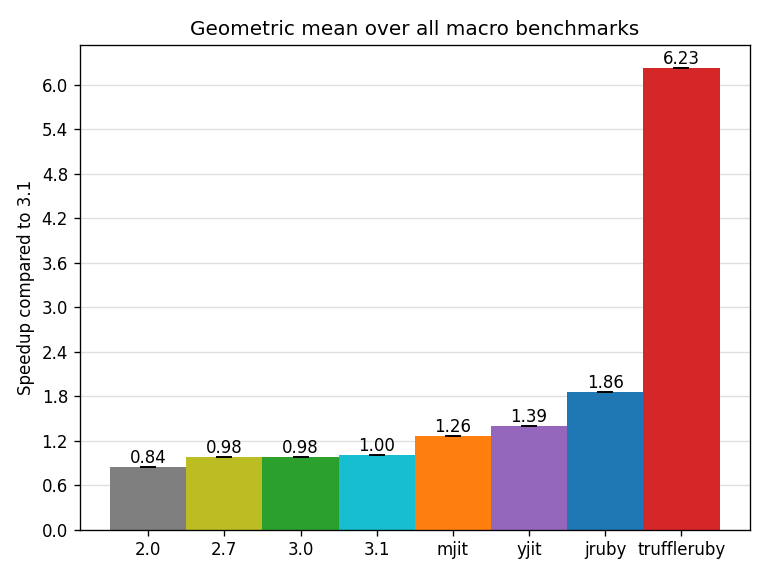
The chart satisfyingly goes higher from left to right. This means, for the geomean on those benchmarks, that newer CRuby versions are faster than older versions, that MJIT and YJIT are faster than without them, that JRuby’s geomean is faster than MJIT and YJIT, and that TruffleRuby is simply in a different league than other Ruby implementations with an overall 6.23x geomean speedup.
On the 7 benchmarks that CRuby 2.0 can run, CRuby 3.1 MJIT is 1.74x as fast as CRuby 2.0’s geomean (binarytrees 1.9x, erubi 1.25x, fannkuchredux 1.33x, nbody 2.17x, optcarrot 3.0x, psych-load 1.12x, rubykon 2.08x). That’s closer to 2x than 3x (i.e., Ruby 3x3) but it is a significant improvement since CRuby 2.0.
Conclusion
I think the numbers speak for themselves.
My take on these results (as the TruffleRuby lead), is that TruffleRuby is able to understand and optimize Ruby code significantly better than any other implementation of Ruby. It seems unlikely other Ruby implementations would ever reach TruffleRuby’s level of performance. TruffleRuby uses the GraalVM JIT compiler, one of the most advanced JIT compilers available today. TruffleRuby, through the Truffle framework, is in direct communication with the JIT (and so are the TruffleRuby and GraalVM Compiler teams) and can easily tell the JIT what is worth optimizing/profiling/inlining and what is not, and when it should deoptimize to the interpreter to reprofile or recompile differently. The Truffle framework makes it much easier to optimize many parts of Ruby. As an example, adding an inline cache is just 2 lines of code (and so TruffleRuby has >100 inline caches), while in other VMs few inline caches are used because of the large complexity involved to add a single one. Finally, the GraalVM architecture makes it possible to inline and just-in-time compile together Ruby code, Java code, C extensions, Ruby regular expressions and any other language implemented on GraalVM, which brings this awesome performance.